



02/01/2023
Descobrim com la Intel·ligència Artificial ajuda a resoldre problemes de testing i quines eines de IA utilitzar per a realitzar els nostres processos.
A CaixaBank Tech seguim especialment de prop els avenços en intel·ligència artificial. Una de les últimes tendències és que la IA està començant a tenir un paper fonamental en el cicle de vida del desenvolupament de programaris i, especialment, en la fase d’avaluació.
Testing: Inestabilidad en los sets de pruebas
La inestabilitat dels sets de proves respecte de les actualitzacions de programari i la dificultat per discernir quins conjunts de prova cal executar segons els canvis en el codi són alguns dels problemes de l’avaluació tradicional. Aquests problemes no només dificulten el manteniment de les proves, sinó que a més alenteixen la fase d’avaluació i, amb això, el temps d’accés al mercat (time to market), perquè s’acaben executant grans subconjunts de proves per provar petits canvis en el codi.
Solucions testing amb IA
Per combatre aquests problemes, actualment s’estan desenvolupant solucions d’avaluació que fan servir intel·ligència artificial per ajudar els desenvolupadors a centrar-se en altres tasques, com ara augmentar la cobertura del codi, cosa que els permet desenvolupar productes de programari de més qualitat amb menys recursos i amb temps de llançament més curts.
Algunes de les tecnologies basades en IA que permeten millorar el procés d’avaluació són les següents:
1. Eines de self-healing
El self-healing (autoreparació) és una tecnologia basada en l’aprenentatge automàtic que permet reparar de manera automàtica els sets de proves quan es produeixen modificacions en el codi de les interfícies gràfiques de les aplicacions o les pàgines web a causa d’actualitzacions en algun dels components.
L’aparició d’aquesta tecnologia està motivada per les excessives modificacions de les bateries d’avaluació que requereixen les eines d’avaluació tradicionals en petites modificacions o actualitzacions del codi. Aquestes eines provoquen que els localitzadors que identifiquen cada un dels elements del web dins dels sets de proves es trenquin i les proves deixin de ser vàlides. Això obliga a malgastar molts recursos de temps i persones en cada actualització i en el manteniment de les proves, cosa que ni és òptima ni en molts casos acceptable. Els frameworks d’avaluació basats en autoreparació (com Healenium) tenen la capacitat d’identificar canvis a la pàgina o la interfície i, per mitjà d’algoritmes d’aprenentatge automàtic (machine learning), poden reparar de manera automàtica les rutes de localitzadors trencats als sets de proves i minimitzar el temps de manteniment, millorar l’estabilitat de les proves automatitzades i permetre que les proves s’adaptin millor als canvis en l’aplicació i l’entorn.
2. Visual Testing basat en IA
Una altra de les tècniques que s’està implantant actualment és l’avaluació visual basada en algoritmes de visió per computador. Però, què és l’avaluació visual? Per què cal fer aquest tipus d’avaluació i quin és el paper que hi té la IA?
Suposem que volem avaluar un web amb 21 elements visuals i que en cadascun volem validar característiques com la visibilitat, l’altura, l’amplada i el color de fons. Si necessitem una asserció de codi per testejar cadascuna de les característiques, ens caldran 84 assercions de codi. Fins aquí, bé… Però ara pensem: en quin navegador es visualitzarà el web? Sobre quin sistema operatiu s’executarà el navegador? Quina és la mida de la pantalla en què es projectarà? Totes aquestes combinacions podrien donar lloc a milers de línies de codi i qualsevol d’aquestes línies podria ser susceptible de modificar-se amb cada nova versió del web, de manera que el manteniment de les proves seria inviable. Per això, necessitem un altre enfocament d’avaluació a banda de l’avaluació funcional: l’avaluació visual.
L’avaluació visual captura la part visual d’un web o d’una interfície gràfica d’una aplicació i la compara amb els resultats esperats per disseny. En altres paraules, ajuda a detectar bugs visuals de la pàgina diferents dels bugs estrictament funcionals. Els errors visuals es produeixen amb més freqüència de la que a priori puguem creure i tot i que els tests funcionals validen el comportament funcional no estan pensats per fer-ho d’una manera òptima amb el renderitzat dels webs. És per això que necessitem tests basats en proves visuals per detectar errors visuals. L’avaluació visual es pot fer principalment de dues maneres: manualment o mitjançant proves automatitzades.
Testing visual manual
Consisteix en proves que un grup de persones duen a terme inspeccionant manualment parells de captures de pantalles per trobar-ne les diferències. Aquestes diferències són realment difícils de detectar en nombrosos casos i quan el nombre de combinacions que cal testejar creix i s’han de provar múltiples pàgines, aquesta manera de procedir és inviable. Per mirar de resoldre aquest problema sorgeixen els tests visuals automatitzats.
Testing visual automatitzat
Aquest tipus de tests (que sorgeix com un intent d’imitar els tests funcionals automatitzats) intenta verificar l’aparença visual d’una pàgina completa, en comptes de les propietats de cada element visual, amb només una asserció de codi. Aquests tests es basen a capturar un mapa de bits d’una pantalla en diversos punts i comparar el codi hexadecimal píxel per píxel amb un mapa de bits utilitzat com a línia base mitjançant un procés iteratiu. Si el codi és diferent, es genera un error.
A diferència dels humans, són capaços de detectar diferències de manera ràpida i consistent, de manera que el manteniment dels conjunts de proves és més senzill. No obstant això, lluny de ser perfectes, aquests algoritmes presenten l’anomenat “problema de prova instantània” o snapshot. Com que els píxels no són elements visuals, els algoritmes de suavitzat de fonts o els canvis de mida d’imatges poden generar diferències en el píxel i fer que el test generi com a resultats falsos positius. Per no parlar de quan en comptes de contingut estàtic també tenim contingut dinàmic (notícies, anuncis, etc.). Per solucionar aquest problema, els últims anys s’han desenvolupat eines d’avaluació visual impulsades per algoritmes d’intel·ligència artificial.
Testing visual automatitzat mitjançant IA
Les proves automatitzades impulsades per IA permeten, per mitjà d’algoritmes de visió artificial, detectar i informar de les diferències entre la renderització final i la visualització prevista per ajudar a focalitzar els tests més exhaustius en els elements que difereixin. En aquest cas, també es fan instantànies de pàgina a mesura que van executant les proves funcionals, però en comptes d’anar comparant píxel per píxel fan servir algoritmes per determina quan s’han produït errors. Gràcies al fet que la comparació està basada en relacions (existència de contingut, ubicacions relatives) i no en píxels, no necessiten treballar en entorns de contingut estàtic per garantir un alt grau de precisió. Un exemple de contingut dinàmic podria ser el de la figura 2, en el qual disposem d’un web d’un diari amb una secció de contingut dinàmic (notícies) que van canviant amb el temps.
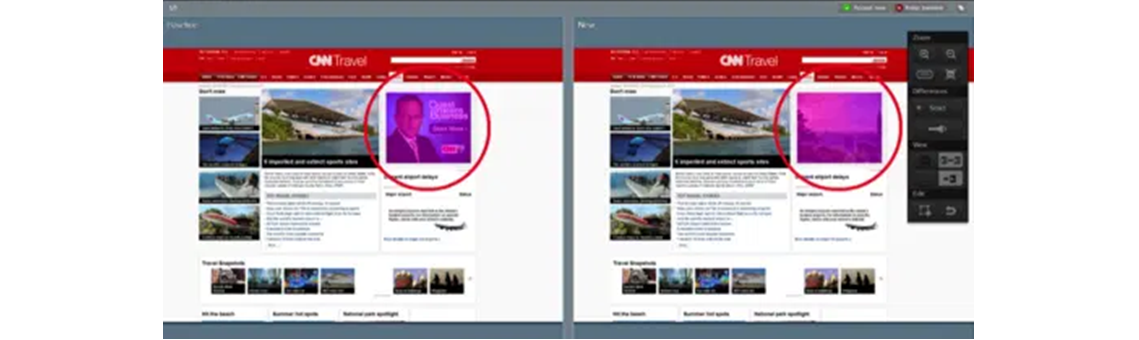
Bots basats en IA
Finalment, l’última tecnologia que presentem és la d’avaluació a través de bots assistits per IA. A mesura que el nombre de línies de codi de les aplicacions creix, el set de proves que cal executar per cobrir la cobertura del codi es dispara i també la dificultat per saber quines proves s’han d’executar segons els canvis de codi. Això comporta en molts casos haver d’executar grans conjunts de proves o, fins i tot, tot el set de proves per assegurar petites modificacions. En altres casos, s’opta per no testejar tots els escenaris afectats amb les possibles conseqüències derivades d’això, atesa la impossibilitat d’establir els criteris que cal seguir per definir quines execucions cal fer en cada cas. Per solucionar aquest problema, actualment s’estan desenvolupant bots basats en intel·ligència artificial i algoritmes de NLP capaços de revisar l’estat actual de les proves, els canvis recents en el codi, la cobertura i altres mètriques, i d’acord amb això decidir quines proves cal executar. Això permet no només reduir els errors en pujades a producció i augmentar l’eficiència en l’automatització de les proves, sinó també reduir el temps de llançament de les versions al mercat.
Malgrat el constant progrés que s’està aconseguint amb intel·ligència artificial en el món de l’avaluació de programari, les tecnologies que hem presentat encara estan en els albors, i encara estem lluny de poder prescindir de l’avaluació manual, que continua sent essencial. No hem d’oblidar que encara hi ha nombrosos entorns en què la contextualització humana és necessària per assegurar un producte de qualitat. Aquestes tecnologies han de ser sempre un suport i no una substitució dels equips d’avaluació. Citant Raj Subramanian, executiu de FedEx: “En comptes que les solucions d’IA substitueixin els equips de control de qualitat, augmentem amb ella la cobertura de les proves de programari”.
tags:
Comparteix:




